В знании сила
В период модернизма возросла уверенность, что эвристические возможности "решателя" проблем определяются представлением в явной форме соответствующих зданий, доступных программе, а не применением какого-то изощренного механизма определения взаимовлияния или сложных оценочных функций. Значительные усилия были направлены на разработку методов разбиения знаний, присущих человеку, на модули, которые можно было бы активизировать по заданной схеме (см. врезку 2.5). Уже при первых попытках сымитировать процесс разрешения проблем, характерный для человеческого разума (например, в работе [Newell and Simon, 1972]), исследователи столкнулись с ограниченными возможностями представления знаний и необходимостью упростить механизм их взаимовлияний, хотя более поздние исследования и помогли в определенной степени преодолеть эти трудности (об этом мы поговорим в главах 11-18).
Стало ясно, что стратегия явного представления человеческого знания в форме направляемых заданной схемой модулей обладает определенными преимуществами перед включением знаний в алгоритм, которые могут быть реализованы с помощью программных технологий, более близких к традиционным.
Ошибки и провалы, обнаруженные в процессе эксплуатации в заложенных в систему знаниях, могут быть скорректированы и заполнены, причем это не влечет за собой кардинальную переделку основного программного кода. Если же в структуре системы не предусмотрена такая "модульность" знаний, их изменения могут повлечь за собой полную реконструкцию системы.
В этот период разработчики на практике убедились в том, как сложно создавать и отлаживать системы, базирующиеся на правилах. По мере расширения базы знаний оказалось, что правила имеют тенденцию взаимодействовать в пределах системы самым неожиданным образом, соревнуясь за приоритет при решении проблемы, что разные режимы управления правилами эффективны для проблем одного типа и не дают эффекта при решении проблем другого типа. Со временем в этом перестали видеть что-то необычное, но поначалу свидетельства такого эффекта воспринимались как анекдоты.
Практический опыт научил нас, что наилучшие результаты при решении проблем разного рода можно получить, только используя отличающиеся методики. Эти методики, получившие звучные и исполненные тайного смысла наименования "эвристическая классификация", "иерархическая проверка гипотез" и "предложение, проверка и исправление", как правило, сводятся к разным стратегиям управления последовательностью применения правил. Эти методики будут подробно рассмотрены в главах 11-15.
2.5. Процедуральное или декларативное знание
В процедурных языках программирования, таких как С, мы, как правило, физически не разграничиваем ту часть программы, которая описывают ее "логику", от той, которая имеет дело с манипулированием данными.
Например, процедура, в которой проверяется, обладает ли данная птица способностью летать, будет выглядеть так:
char fly(char s)
{
char answer = 'д'; if (strcmpfs, "пингвин")==0)
{ answer = 'н';} return answer;
}
Независимо от того, владеете вы языком С или нет, понятно, что этот программный код явно вызывается другой частью программы, например, так:
char с;
с = fly("пингвин");
Предположим, что вместо этого у нас есть два правила, которые хранятся в базе знаний:
(defrule
(птица (тип ?Х)) =>
(assert (да))
)
(defrule
(птица (тип пингвин)) =>
(assert (нет)) )
В этом примере форма правил более близка к объявлению или определению (использован- синтаксис языка CLIPS). Для случайно выбранной птицы утверждается, что она способна летать. Но если известно, что птица — это пингвин, то утверждается, что она не способна летать. Но поскольку пингвин это тоже птица, то какой-то другой компонент экспертной системы должен решить, какое из этих двух правил применять в данной ситуации. Этот компонент называется машиной логического вывода (inference engine).
В этом примере совершенно отчетливо видна модульная природа правил. Код, который в явном виде вызывает то или иное правило, отсутствует. Подробно реализация таких правил будет рассмотрена в главе 5.
В этот период появился ряд систем, которые довольно эффективно справлялись с нетривиальными задачами. Примером может служить система R1/XCON, предназначенная для структурного синтеза вычислительных систем (подробно о ней — в главе 14). В этой системе реализован ряд концепций, существенно отличающих ее как от обычных программных приложений, так и от исследовательских программ искусственного интеллекта (см. [Davis, 1982]). Те, которые я считаю наиболее важными, перечислены ниже.
В частности, можно добавлять в базу знаний новую информацию, расширяя имеющиеся в системе знания, или настраивать механизм логического вывода, повышая его эффективность, и при этом не модифицировать программный код системы.
2.6. Машина логического вывода и база знаний
Как правило, в структуре экспертной системы можно четко разделить базу знаний и компонент, который этой базой пользуется, — машину логического вывода. Взаимодействие между ними обеспечивается программой, которую принято называть оболочкой (shell) экспертной системы.
Конечный пользователь приложения взаимодействует с системой через оболочку, передавая ей запросы. Последняя активизирует машину логического вывода, которая обращается к базе знаний, извлекает знания, необходимые для ответа на конкретный вопрос, и передает сформированный ответ пользователю либо как решение проблемы, либо в форме рекомендации или совета (рис. 2.5).
В базе данных содержатся правила и всевозможные декларации. В частности, применительно к примеру "Пингвин", представленному во врезке 2.5, в базе знаний, организованной с помощью языка CLIPS, должны присутствовать следующие декларации:
(deftemplate птица (field (тип SYMBOL)))
в дополнение к имеющимся правилам:
(defrule (птица (тип ?Х))
=>
(assert (да))
)
(defrule
(птица (тип пингвин))
=>
(assert (нет)) )
Из этой декларации следует, что объект данных птица может содержать поле (field) тип. В главе 5 вы познакомитесь с декларациями другого типа, которые служат для настройки поведения машины логического вывода.
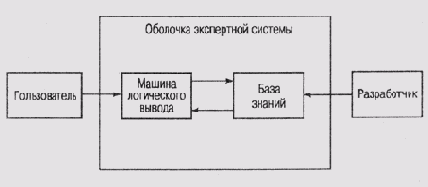
Рис. 2.5. Структура экспертной системы
